Depth First Search
Problem #155
✰ - click to bookmark
★ - in your bookmarks
Tags:
graphs
data-structures
c-1
c-0
popular-algorithm
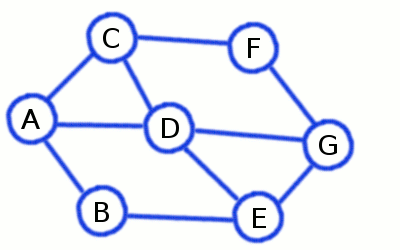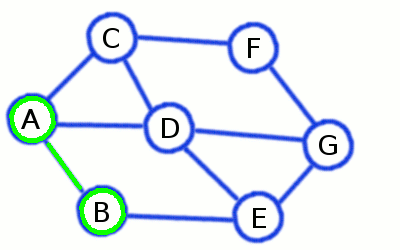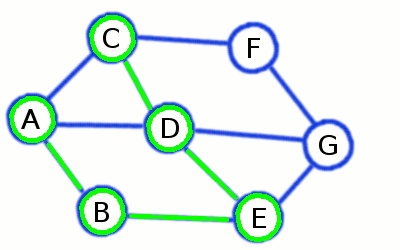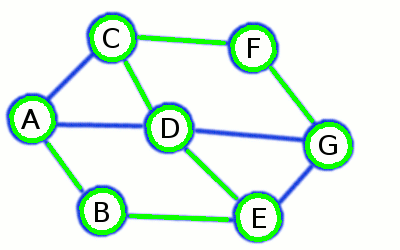
Depth First Search builds a long and skinny spanning tree
Depth-First Search with its complement Breadth-First Search are two popular methods of searching in the graph. It is recommended to solve the exercise on BFS first.
The Depth-First words in the title of the algorithm explain its behavior. For each discovered vertex it tries to choose any single neighbor node and proceed searching from it. Searching from via other neighbors is carried out only after the chosen branch is completely investigated.
This algorithm also builds spanning tree (if the graph is connected), but unlike BFS it creates long branches (though few of them). If we are lucky as with graph represented on the picture above, the whole tree could contain a single branch at all!
This makes the algorithm unsuitable for searching shortest paths. Though in some cases it is convenient when we want to check the existence of any path between two nodes.
The problem of finding the loop (or loops) in a directed graph is easily solved by DFS while BFS can instead give us not a loop but two paths to the same vertex. Of course if the graph is undirected it will also be a solution.
Algorithm Implementation
Nice thing is that we need only slight modification of BFS to convert it to DFS:
- we should use a
Stackinstead of theQueuefor storing vertices; - we do not check whether node was
seenwhen storing neighbors in the stack - instead we perform this checking when retrieving the node from it.
You probably know that the Stack is similar to Queue, but the elements are retrieved in the reversed order, which
is often called LIFO, i.e. Last in, First out. If we add elements to the end of array and retrieve it from the
end also, then it is just the implementation of the stack.
So here is the detailed steps of the algorithm:
- We add the initial node to
stack. - Remove the next element from the
stackand call itcurrent. - If the
currentnode wasseenthen skip it (going to step6). - Otherwise mark the
currentnode asseen. - Get all neighbors of the
currentnode and add all them tostack. - Repeat from the step
2until thestackbecomes empty.
You also can read wikipedia article to get more clear idea.
Problem Statement
Again you should produce the array representing the spanning tree built by the algorithm. There are different ways to extend the algorithm to allow it remember where you came from to which nodes.
To avoid ambiguosity please take care that neighbors should be tried in order of increasing their ids (like in BFS problem).
Input data will contain the amount of nodes N and the amount of edges M.
Then M lines will follow each containing ids of two nodes connected by an edge. Node ids are integers between 0 and N-1.
Answer should contain the array of values: a[i] should contain the index of the node from which i-th one was
visited by the algorithm. It should have -1 for the initial node, i.e. a[0]=-1.
Example:
input data:
7 10
0 1
2 0
0 3
1 4
4 3
2 3
5 2
6 3
4 6
6 5
answer:
-1 0 3 4 1 2 5
This example is relevant to the graph represented in the picture, but letters are substituted with the integers.
Another example:
input data
4 4
0 1
1 2
3 1
2 0
answer
-1 0 1 1
Here we go from node 0 to 1, then from here to 2 and this node appears to be "terminal" - it have no unvisited
neighbors, so we track back to node 1 and from here visit the remaining 3.